A certain type of crossword has been catching my attention ever since I was little. But it never interested me much to sit down and solve it on paper. What I wanted to do was to write a program that helps me solve it or, even better, one that finds the solution itself.
Twenty years ago, very early in 1997, I wrote a Pascal program for DOS that set a high resolution text mode (132x60!) and drew the crossword on the screen along with a frequency analysis. It had two commands: give a letter to a number or highlight a number.
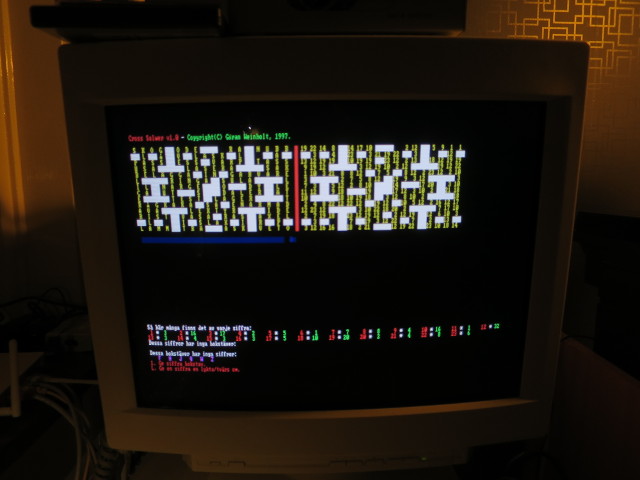
I rang in a few answers to the newspaper, but I never won and it was still tedious work to solve the puzzles. Now that we live in the future computers are more powerful and should be able to solve the crosswords on their own. Or at least with some help from a programmer instead of the other way around.
Artificial Intelligence is a strange thing. In some meaning of the word it’s basically just a bunch of different search algorithms that work for different problems. If you open a book on AI, that’s mostly what you’ll get. In another meaning it’s the idea that the computer will not need to be programmed and will figure everything out itself. We’re not quite there yet.
| 19 | 22 | 14 | 8 | 14 | 17 | 10 | 15 | 2 | 12 | 5 | 9 | 1 | 1 | ||||
| 3 | 4 | 23 | 3 | 21 | 19 | 22 | 3 | 15 | 12 | ||||||||
| 13 | 12 | 19 | 19 | 10 | 19 | 19 | 23 | 12 | 2 | 13 | 18 | 12 | 19 | 19 | |||
| 9 | 19 | 12 | 3 | 12 | 19 | 10 | 2 | 12 | 19 | 12 | 22 | ||||||
| 1 | 10 | 3 | 21 | 8 | 8 | 12 | 7 | 5 | 8 | 12 | 2 | 23 | 12 | 2 | 10 | ||
| 3 | 2 | 7 | 5 | 8 | 12 | 19 | 9 | 3 | 12 | 3 | |||||||
| 7 | 3 | 5 | 14 | 2 | 8 | 10 | 14 | 17 | 20 | 3 | 10 | ||||||
| 11 | 12 | 9 | 18 | 19 | 17 | 12 | 3 | 10 | 2 | 21 | 18 | ||||||
| 10 | 18 | 10 | 19 | 18 | 3 | 12 | 8 | 10 | 2 | 18 | |||||||
| 2 | 4 | 8 | 22 | 12 | 22 | 12 | 19 | 12 | 10 | 5 | 12 | 2 | 16 | 12 | 17 | ||
| 12 | 24 | 12 | 3 | 10 | 22 | 18 | 20 | 2 | 7 | 17 | 10 | ||||||
| 2 | 15 | 19 | 18 | 23 | 12 | 19 | 12 | 2 | 12 | 19 | 12 | 6 | 10 | 3 | |||
| 2 | 15 | 7 | 19 | 3 | 12 | 22 | 7 | 2 | 13 | ||||||||
| 3 | 12 | 16 | 16 | 18 | 2 | 21 | 12 | 19 | 22 | 23 | 10 | 18 | 14 |
The crossword above comes from a 1997 newspaper, and they are still in the newspapers every week. Each square in the crossword has a number that represents a letter in the alphabet. A crossword of this type is called a coded crossword or a cipher crossword and there are several ways one could go about solving these. We’ll be using a genetic algorithm which, even though it works, is not a perfect match for the problem.
The algorithm will have these parts: alphabetic strings that will be called individuals, generations of individuals, a fitness function and a mixing function. The fitness function is used to measure which individuals are the best at solving the crossword. The mixing function will combine two individuals in an attempt to make a better one. All this is pretty standard for a genetic algorithm.
Individuals matter
We’ll need some individuals. The first individuals will simply be pulled from the void by the chaos of randomness. For a coded crossword it would be smarter to generate the initial individuals based on known statistics of letter frequency. So the program would count how many times each number shows up in the crossword, and guess that it will more or less match the letter frequency of words. So the most common number would probably be E, followed by T, and so on. But pulling them from the void is actually easier and sounds cool. Here’s one right now:
The idea is that the first letter corresponds to all 1’s in the crossword, the second letter to all 2’s, etc.
(Apologies if this individual is being rude to you: they have a very short life cycle and it will be gone before you know it!)
Get the words to measure
Now we’ll need a fitness function. In general one of the inputs is an individual and the output should be some measurement, which should be commensurable (yeah — possible to compare) with the fitness of other individuals. The rest depends completely on what the problem is. The correct solution to the crossword should contain legible words, so let’s use a dictionary to see how close the individual is to finding words.
The code will actually be demonstrated on this webpage, so if you are reading the article online you can experience the solver yourself. First we’ll need a list of all words on the board, except that the words will be lists of numbers instead of actual strings. The board is a simple table in the web page. Here’s the ECMAScript 6 (JavaScript) code that first converts the table to two simpler representations of the board and then finds the words:
function get_numeric_words(selector)
{
let board = new Board();
let rotated_board = new Board();
// Get the numbers from each coordinate i,j
$(selector + ' tr').each(function (i) {
$(this).find('td').each(function (j) {
board.put(i, j, this.innerHTML);
rotated_board.put(i, j, this.innerHTML);
});
});
return [...board.find_words(), ...rotated_board.find_words()];
}
Words can run from either left-to-right or from top-to-bottom, so a
rotated board is also created. The Board helper class follows. It
doesn’t need to care about searching from top-to-bottom since a
different rotated board does that.
class Board {
constructor() {
this.digits = [];
}
put(i, j, v) {
// Put a number at the coordinate i,j
if (this.digits[i] === undefined) {
this.digits[i] = [];
}
this.digits[i][j] = v;
}
find_words() {
let word = [];
const words = [];
// Loop over all coordinates in the board.
for (var i in this.digits) {
for (var j in this.digits[i]) {
let digit = this.digits[i][j];
if (digit === "") {
// Words end when there's a blank.
if (word.length > 1) {
words.push(word);
}
word = [];
} else {
word.push(digit);
}
}
// Words end at the end of the line.
if (word.length > 1) {
words.push(word);
}
word = [];
}
return words;
}
}
The method find_words() looks for groups of numbers, so a word needs
to be at least two numbers next to each other. Here are the first and
last words found by the function:
19,22,14,8; 14,17,10; 15,2,12; 5,9,1,1; 3,21,19,22; …; 16,7,6; 1,12,19,12,2; 3,21; 12,17,10,13,18; 19,22,10,3,10,18,18,17,10,3
These can now be translated into real words by using an individual.
The translate() method is very simple. It maps each number to the
corresponding letter in the individual and then turns them all into a
string with .join(). Here’s a very simple Individual class that
can translate a word:
class Individual {
constructor(letters) {
this.letters = letters;
}
translate(word) {
return word.map(number => this.letters[number]).join('');
}
}
The individual that was pulled from the void a little bit earlier in the article is quite unlikely to be the one that we are searching for. The void happens to contain somewhere around factorial(29) individuals:
8 841 761 993 739 701 954 543 616 000 000 individuals
This is commonly written “29!”. Only a handful of these are winners
and the rest are a bunch of sore losers out to ruin your day. Here’s
the table of words from above now run through the translate()
function. If this list contains legible words then you should probably
run and buy a lottery ticket:
BÖYÄ, YSZ, UTA, OWXX, CNBÖ, …, IFG, XABAT, CN, ASZÅL, BÖZCZLLSZC
The very large number of undesirable individuals is also what makes it difficult to find the right ones. But if there is a solution at all to the crossword then these undesirables have very nice neighbors that we’d like to meet.
The measure of an individual
Whereas in real life it’s very difficult to judge a person’s character, and we may mistakenly believe that the beautiful is always good, in this game we need to simply define a measure of how close the individual’s answer is to the truth. And for that we need to know what the truth looks like.
Crosswords contain words, so a very simple measure is to translate the crossword with an individual and check how many correctly spelled words it found. But since we are intelligent beings our temptation is of course to make a more interesting measure. We want to guide the algorithm towards the truth with our own insights about how things work.
It could work as follows. Suppose that we take all the words in the dictionary and all the words in the crossword and map them to the same alphabet. Then if you found “hello” in the dictionary it would be written as “abccd” and if you found [10, 18, 4, 4, 13] in the crossword it would be also written as “abccd”. And then you may look up “abccd” in a hash table and see what the closest translated word is, and perhaps you get “hillo” and decide that this counts as a ⅘ match for that word. Then you sum this up over all words and that’s the fitness.
It certainly defines a measure, and maybe it works, but it turns out that speed is very important in this part. Just like in real life things are much faster, we usually know in just a few seconds if we like someone. There are a lot of individuals that we need to meet before we find the right one and we might be capable of falling in love with, let’s say, one out of a thousand people, but here it’s a handful out of 8 nonillion 841 octillion 761 septillion 993 sextillion 739 quintillion 701 quadrillion 954 trillion 543 billion 616 million individuals that have the answer we’re looking for. The odds are not in our favor.
The algorithm depends quite a bit on raw throughput, so as to
efficiently measure as many individuals as possible. So it’s better to
define a fast and simple measurement. For this purpose a large
dictionary was used and then filtered against the most common words
found in Wikipedia, merely to cut down the size of the download. (Then
some slight trickery was done: the words from the solved crossword
were added, but only for cosmetic reasons so that progress will reach
100% when the solution has been found). Here is the new Individual
class with the measure method that computes the fitness to between
0.0 and 1.0:
class Individual {
constructor(letters) {
this.letters = letters;
this.fitness = undefined;
}
translate(word) {
return word.map(number => this.letters[number]).join('');
}
measure(words) {
// Calculate the proportion of correctly spelled words.
let matches = 0;
for (let word of words) {
if (dict_set.has(this.translate(word))) {
matches++;
}
}
this.fitness = matches / words.length;
}
}
Connecting individuals
The individual from earlier in the article can now be measured, and it turns out that its fitness is 1.19%. Now it’s time to generate new individuals. (Although in some way they are not actually new, because we know exactly how many individuals there are). One way is to keep pulling random individuals out of a hat until we find the right one. That’s called brute force and it doesn’t work here due to the large number of individuals. Instead we will combine the best of the best individuals and hope that the combinations are better than their predecessors.
The basic idea is that some of the best individuals really like each other and make new individuals. (Don’t look too closely for metaphors with real living creatures here, it gets really naughty and brutal). If we look at the individuals they have a sequence of letters and it’s not too different from how DNA works. If we have two partners then we can make a new individual by randomly picking DNA letters from them. In the following algorithm there is a 50% chance that a letter comes from the individual itself, a 50% chance that it comes from the partner, and dependent on that a 10% chance of a random mutation.
class Individual {
...
make_child(partner)
{
const a = this.letters;
const b = partner.letters;
const ret = b.split('');
for (let i in a) {
if (Math.random() < 0.5) {
if (Math.random() < 0.1) {
// There has been a random mutation.
i = Math.floor(Math.random() * a.length);
}
// This letter will be picked from the partner.
let cm = a[i];
let cf = ret[i];
let j = ret.findIndex(x => x == cm);
ret[i] = cm;
ret[j] = cf;
}
}
return new Individual(ret.join(''));
}
}
Now a large number of individual need to be generated and measured. This part of the algorithm has some interesting challenges. Just like ourselves it tends to get stuck on some particularly good idea it has. It may have found a solution that makes 40% of everything on the board look like it’s a word, but then it never gets any further. In retrospect it will turn out that these 40% correct words were actually supposed to be some completely different words altogether. It got stuck at what’s called a local maxima. There is sometimes no way to go forward from such a local maxima because the distance between it and the way forward is simply too large, and any individual closer to the truth will temporarily decrease the fitness. In other words: they’ll sound wrong, but their ideas lead to progress.
For this reason disasters have been incorporated into the algorithm. The algorithm itself is otherwise pretty traditional. It works with generations of individuals which it processes in something that smells like natural evolution. It takes the previous generation, adds 100 random individuals so that there will always be something to work with, and has everybody make children (according to the previously described method). Afterwards only the best of the individuals make it to the next generation. The previously described disaster strategy is implemented by completely randomizing the percentage of individuals that will survive for the next generation (it’s even possible for the best individual to be wiped out like a dinosaur).
function evolve(previous_generation, words)
{
// Pull some new completely random individuals out of the void.
const random_folks = Array(100).fill(1).
map(_ => Individual.random());
let individuals = [...previous_generation, ...random_folks];
// The survivors and the newcomers make children.
random_folks.forEach(individual => individual.measure(words));
for (let i in previous_generation) {
for (let j = 0; j < individuals.length &&
j < previous_generation.length; j++) {
const child = previous_generation[i].
make_child(individuals[j]);
child.measure(words);
individuals.push(child);
}
}
// Get the best of the generation. Only a few of the
// individuals survive, due to random disasters.
individuals.sort((a, b) => b.fitness - a.fitness);
return [individuals,
individuals.slice(0, Math.floor(Math.random() * 100))];
}
In general the size of the generations varies greatly, from thousands to a few dozen.
Running the algorithm
The algorithm can be run in the browser by pressing the start button below. The current champion of all time is shown, along with its solution, and the progress bar shows the fitness of the best individual of the latest generation. The JavaScript console also has logs of the progress.
Conclusion
The algorithm tends to run to finish in somewhere around 10—40 generations, but it can take quite a bit more time than that. Even though the search space is enormous the algorithm only ever looks at a minuscule part of it, perhaps around 100 000 individuals. Some insights:
- The initial individuals can be completely random. Any effort to improve them is a wasted effort, the algorithm will do it automatically.
- A very simple fitness function was enough and there was no need for a more intelligently designed and intricate function.
- Sometimes the algorithm gets stuck and needs to start over. In those cases the individuals that would lead towards a solution are simply worse than the best available individual, even though that individual is at a dead end.
- The algorithm contains some unmotivated parameters, such as 100 random individuals and a maximum generation size of 100. The probabilities are also unmotivated. The 50% number is based on knowledge about natural processes, but there is no special reason why the same probabilities should be used for this problem.
The algorithm is a genetic algorithm, and there is something more that we could have hoped for it to do. Our individuals are unfortunately only going to be experts at solving a single crossword, so for each new crossword it will be necessary to run the algorithm again. This is because the fitness function simply changes too dramatically if the crossword is replaced. If a genetic algorithm is applied to other problems it is sometimes possible to let loose the best individual and have it solve problems it has never seen before.