I find it useful while working in Python, JavaScript or C to have Emacs show me the location of code errors. For Python there is Pylint and for JavaScript one can use JSHint and a few others. And of course with C there was the original lint, but today the compilers themselves generate quite good warnings. These linters are easily integrated with Emacs via Flycheck, which highlights errors in the code. Finding that they produce too many errors when fed Scheme code, I decided to make my own linter, r6lint.
Some normal things are expected from a linter:
- It should not produce irrelevant messages.
- It should show the location of the problem.
- It should do some useful analysis.
I wanted my linter to warn about bad style (possibly according to Riastradh’s Lisp Style Rules), improper usage of procedures and to show the location of unused variables. This last part is something that even the original lint did. Of course, a linter performs static analysis and this limits what it can do. But it should at least find some problems that compilers don’t bother to warn about. And a linter can be a social tool, helping to spread awareness of good style.
Practical issues
Scheme is pretty good for working with Scheme code, but in this case
the tools in the standard library are not adequate. The read
procedure that parses S-expressions does not keep the source
information, so e.g. the location of procedure definitions would be
lost. The linter needs this information and that means a custom reader
must be used.
Scheme is not limited to the syntax provided by the language designer
and compiler implementer. Code can define new syntax and package it
in libraries. R6RS Scheme supports syntax-case, which allows macros
to run arbitrary code at compile time. These can introduce new
variables and control structures. If the linter didn’t understand
these then the analysis would be very lacking. So when the parsed
S-expressions are in memory they need to be macro expanded.
The macro expander is however not exported by the standard libraries. One of the reasons for this is that the output from the expander is very implementation-specific. Exposing the macro expander wouldn’t automatically mean that programs could do anything useful with its output, because the forms it returns do not need to be standard Scheme forms.
Practical solutions
I happened to already have a lexer and parser for R6RS and for this project I’ve improved it so that it keeps source information. I also modified the reader be tolerant to errors, so it can emit more than one error message. If packaged separately it should be called tra-la-la, because it will happily ignore all possible errors and continue reading until end of file.
The next part of the solution is a macro expander. For this I dug up the portable syntax-case implementation by Abdulaziz Ghuloum and R. Kent Dybvig. The official code repository is in Launchpad as lp:r6rs-libraries, but some fixes and improvements can be found in the psyntax embedded in Ikarus and IronScheme.
I made my own modifications to psyntax. There is a small change in how
source information is handled so that the reader’s annotations can be
used. Furthermore there is no longer any need for compatibility
libraries. One assumption of psyntax is that it will be integrated in
a Scheme implementation. This means that it needs access to a lower
level of the Scheme implementation than is accessible from R6RS. It
wants to read and set top-level variables that are reachable from
eval‘d code (it uses eval to run user-provided macros). In R6RS
there is no portable interaction environment, which would normally
provide this kind of semantics. I’ve worked around this by placing
macro-defined global variables in a hashtable.
Another problem is that psyntax needs to generate unique symbols. This
is an important feature for syntactical hygiene: if a macro contains
the variable x it should not clash with the macro user’s variable
x. In R6RS there isn’t really a gensym, but macros still need to
be able to generate temporary names, so access to the host Scheme’s
gensym can more or less be finagled by using the standard procedures
generate-temporaries and syntax->datum. A requirement from the
linter (not psyntax) is that a gensym must be possible to turn back
into the original symbol. In Chez Scheme this isn’t a problem due to
an innovative gensym that works with symbol->string. But generally
in other implementations the name returned could be anything, so the
linter saves all gensym names in a hashtable.
Finally the output from psyntax is records instead of S-expressions. In part this eliminated the need to represent the void value, but primarily it was useful to get a more general way to store source information.
Lint it
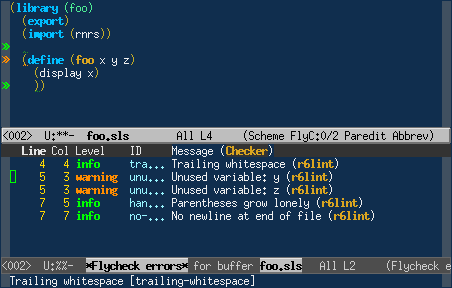
In r6lint the analysis happens on several levels. The lexer itself warns about lexical violations, e.g. unexpected end of file, characters outside the valid Unicode range and invalid identifiers. The reader finds problems with mismatching braces and other structural problems. The tokens from the lexer are also used to detect formatting errors, e.g. hanging parenthesis, trailing whitespace and other whitespace issues.
Syntactical violations are reported during macro expansion. Exceptions from the expander are caught and transformed into something useful. This doesn’t do much more than a compiler already does, except it tries to preserve source information.
The more interesting analysis has barely even been implemented, but a proof of concept is there. The records returned by psyntax are fed into a simple analyzer that warns about unused variables.
Wonders
I integrated the linter with my editor before it was working. At one point while I was coding the linter sprang to life and started to warn about errors in itself. This sort of thing tends to happen a lot with Scheme.
In summary there is a new R6RS Scheme frontend that is designed to run standalone in any R6RS implementation. It feeds a simple static analyzer where new analysis passes can be plugged in. It’s an interesting framework that I hope will grow more and more featureful.