There are times in a programmer’s life when he needs an API to an intranet service and the only existing interface is a website built in the 90s. It feels wrong and a little dirty. But it may be the only option. It will save the business. Against better judgment, you decide to try web scraping their site.
So you connect a socket to their web server and send a GET request. The response contains comments about features that were never deployed, notes on fixes for bugs ten years old written by “jim”, and the line endings are a mix of Windows, Unix and classic Mac style. With the response in hand you reach into your toolkit and pick out the regex library. Then the madness starts and the hacks begin to pile up. Disaster lies ahead. You should have known better than to try web scraping. You give away all your possessions and become a Buddhist monk.
“Serenity Now!”
It doesn’t need to be a dirty mess. By following a few simple rules, and using the right tools, it can be a clean mess that will stand the test of time. Here’s a high-level view of the workflow:
- Decide on a feature that your API will implement. It can be to read or post some data on the site.
- Start the network monitor in your browser and use the site manually do to what you want your API to do. Save the requests to archives.
- Analyze the archives and document the requests you need for your task.
- Write unit tests for parsing the relevant responses in the archives.
- Write parsers that operate on syntax trees and that don’t break if the style or language of the page changes.
- Write methods that perform requests towards the service, and which hide non-business attributes of the service.
- Write classes that represent objects in the service, and which also hide non-business attributes of the service.
- (Optionally) Write a server implementation that acts like the remote service, for use in automated tests.
All major web browsers have a network monitor in the developer tools, but in a pinch even Wireshark would work. There are a few tools for Python that help with these tasks. Let’s have a look at the steps in more detail.
Document the site
I will show how to create a Python API for LIBRIS, the database for the National Library of Sweden. (Mostly because I don’t think they will mind very much – they also have real APIs). First go to http://libris.kb.se/ in Firefox and press Ctrl-Shift-Q. Mark HTML and XHR to see only the requests that usually matter. (The preference “Enable persistent logs” under the cog wheel icon should also be enabled). Fill in the search box and press enter:
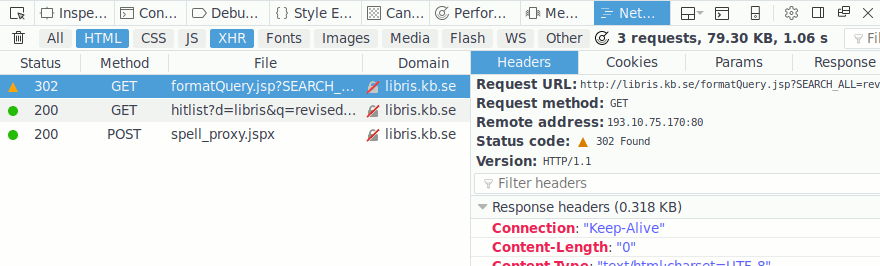
Right click a request and “Save All As HAR”. This creates a file in JSON format that contains all requests made in this session. Reading it you find this interesting request and response:
"request": {
"bodySize": 0,
"method": "GET",
"url": "http://libris.kb.se/formatQuery.jsp?SEARCH_ALL=\
revised+report+scheme&d=libris&f=simp&spell=true",
"httpVersion": "HTTP/1.1",
...
"response": {
"status": 302,
"statusText": "Found",
"httpVersion": "HTTP/1.1",
"headers": [
...
{
"name": "Location",
"value": "hitlist?d=libris&q=revised+report+scheme\
&f=simp&spell=true&hist=true&p=1"
},
The parameter SEARCH_ALL is clearly your query, but you don’t know and don’t really care what the other parameters are. They are just part of the request.
This particular response is a redirect to another location, so you also need to find that request:
"request": {
"bodySize": 0,
"method": "GET",
"url": "http://libris.kb.se/hitlist?d=libris&\
q=revised+report+scheme&f=simp&spell=true&hist=true&p=1",
"httpVersion": "HTTP/1.1",
"response": {
"status": 200,
"statusText": "OK",
"httpVersion": "HTTP/1.1",
...
"content": {
"mimeType": "text/html; charset=UTF-8",
"size": 40565,
"text": "<!DOCTYPE ..."
...
The response is an html document. Inspection of the “text” part of the response shows that it contains the search results. The text field should be saved to a file for later testing of our parser. Now you can write down how to perform a search:
Searching
Send a GET request to http://libris.kb.se/formatQuery.jsp
Use the following query parameters:
SEARCH_ALL=revised+report+scheme
d=libris
f=simp
spell=true
This redirects to /hitlist, which contains the search results.
For this request you could have used the visual tools in the network monitor but, if the site is rather serious about frameworks and such, then it can become quite difficult to find out exactly how everything fits together. You might find that the request you’re interested in uses some id parameters that are hard to track down. The benefit of the HAR file is that you can search for the data you need using your editor of choice.
Parse the responses
The responses from the server should be saved to files exactly as they arrived over the network. They are going to be the basis for test cases. Here’s one way you can write the test in Python:
# test_libris.py
import libris
import unittest
class TestApiParsing(unittest.TestCase):
def test_parse_hitlist_1(self):
with open('hitlist_1.html') as f:
parser = libris.parse_hitlist(f.read())
result = list(parser)
expected = []
self.assertEqual(result, expected)
if __name__ == '__main__':
unittest.main()
It’s not clear what the expected result is just yet. You could of course read the page and try to construct an expected result. But it will be faster to simply pretty-print the actual result later and paste it into the test. Let the computer do the tedious work.
The test will not pass without the parser, so let’s write it. The server gave us back html and you need to extract the good parts from it. You don’t want to be reliant on the exact formatting of the html, since the people who maintain the service might want to change it.
Beautiful Soup is a library that makes it really easy to work with html and xml in Python. Our parser can easily find relevant elements in the document and extract text and attributes from them. But more importantly, it makes it easier to make a parser that is tolerant to changes in the html.
# libris.py
from bs4 import BeautifulSoup
def parse_hitlist(html):
"""Parses a hitlist from a search."""
soup = BeautifulSoup(html, 'html.parser')
form = soup.find('form', id='trafform')
headers = [th.text for th in form.table.thead.find_all('th')]
for tr in form.table.tbody.find_all('tr', recursive=False):
columns = (list(x.stripped_strings) for x in
tr.find_all('td', recursive=False))
yield dict(zip(headers, columns))
This is a pretty basic parser that turns a table into rows of dicts.
There’s a lot happening in very few lines: it looks for a <form/>
element with the id attribute “trafform”. It then gets the text from
every th in the table’s thead, and finally iterates over head tr
in the tbody, yielding a dict for each row.
The goal should be to get rid of the markup. Imagine that you had a REST API for the service. What would it return for a search? Probably enough to let you decide if the result is interesting and something that lets you look up more information on the result. This is what the parser needs to extract.
The output from the parser is unfortunately not adequate. Here’s the first result:
{'Hitta': ['1\n'
' '
' '
'bibliotek'],
'Numrering': ['1.'],
'Omslagsbild': [],
'Referens': ['The revised revised report on Scheme or '
'An UnCommon Lisp / by '
'Hal Abelson ... ; William Clinger (editor)',
'1985',
'Bok']},
There’s just not enough information here. It is indeed a search hit,
but if that is all that’s returned then you would be stuck. In
particular, you don’t know how to request more information about the
search hit. To find out what’s going on you can add the code
print(tr.prettify()) to the loop. It turns out that the rows are
full of metadata:
<tr>
<td class="numrering">
1.
<input class="checkbox" name="post"
type="checkbox" value="8928329"/>
<abbr class="unapi-id" title="8928329">
</abbr>
</td>
<td class="cover">
<a href="showrecord?q=revised+report+scheme&r=
&n=1&id=8928329&g=&f=simp
&s=r&t=v&m=10&d=libris">
<img alt="Omslag" src="https://xinfo.libris.kb.se/
xinfo/xinfo?type=hitlist&identifier=libris-bib:8928329"/>
</a>
<br/>
</td>
<td>
<ul>
<li>
<a href="showrecord?q=revised+report+scheme
&r=&n=1&id=8928329&g=&f=simp
&s=r&t=v&m=10&d=libris">
The revised revised report on Scheme or
An UnCommon Lisp / by Hal Abelson ... ;
William Clinger (editor)
</a>
...
These elements can be extracted with code similar to this:
unapi_id = tr.find('abbr', attrs={'class': 'unapi-id'}).attrs['title']
cover = tr.find('td', attrs={'class': 'cover'}).img.attrs['src']
At this point there can be any number of fields that appear, many that
probably can be ignored. But some of them will be needed to look up
the record for a search hit. This metadata should be added to the
results from the parser. If you can find the html elements by matching
on their id or class attributes then the code will generally be
more robust to changes. Beautiful Soup also accepts regex objects when
filtering on attributes, which can make the parser more robust.
There’s another thing that will help you debug issues later. The
parser as written just assumes that all elements are found. But if the
server one day stops sending <form/> elements (perhaps just for some
responses) the parser will crash with a hard to debug
AttributeError. It’s better to write if statements that explicitly
raise an exception when the expected elements or attributes are missing.
The test will fail since it expects an empty list, but now you can
pprint the actual result from the parser and paste it into the test
file. Visually inspect the result to see if it makes sense.
Try to think of special cases for testing. What if there are no hits? It’s quite common that the html will look radically different when there are no search hits. Add that as a test case. What about when there’s only one hit?
The benefits of saving and testing against actual results come later when you discover that there are more variations in how the server sends data. Then you want the parser to still work for all old data, but to also accept the new data.
A last note on parsing. Most sites will have snippets of JavaScript
that contain important information. These are usually not a blocker.
Beautiful Soup can find the <script/> tags for you. Then you extract
the needed information from the text, e.g. using a combination of
regexes and a JSON parser.
Ask and you shall receive
Now that you have a parser for the responses it is time to start sending http requests. Here another Python library is immensely helpful: requests. For any more advanced site, e.g. one where you need to log in, you will want to handle session cookies. Some sites are also implemented using server-side session data and use cookies to keep track of which session you belong to.
In the spirit of cooperation, I strongly suggest that you add a User-Agent header that tells the server operator how to contact you. The server might be scaled for manual use only and perhaps your use of the site will be particularly difficult to handle. Suppose there is an advanced search form and you use it in a clever way to get exactly the data you need. Unfortunately it turns out the developers of the site took a shortcut and this query you’re making is now the heaviest load the site has ever seen. It’s better to get a friendly email or phone call than to be completely blocked from the site.
And while updating the User-Agent, there’s a trick you can try. Some sites (he said, looking towards Redmond) work normally only if you add Mozilla/5.0 to the User-Agent. With most intranet-style sites you can get away with simply following the http standard, but in a more adversarial situation you might need to make the requests look completely, 100% identical, to what the web browser would send.
Let’s continue with the LIBRIS API. Create a class that will be the main entry point for your API. The constructor will initialize the session, perhaps taking care of logging in, and a method will perform searches. The method is based on the documentation you created previously, together with the parser for the responses:
# libris.py
import requests
import urllib
class LibrisApi(object):
"""An API for LIBRIS
Note to fast and loose copy-pasters: LIBRIS has a real API.
Don't use this one in production.
"""
def __init__(self):
self.session = requests.Session()
self.session.headers['User-Agent'] = \
'Mozilla/5.0 python-requests/' + requests.__version__ + \
'LibrisApi/1.0 <myTeam@example.com>'
self.base_url = 'http://libris.kb.se/'
def search(self, query):
"""Searches for books.
:param str query: A query string for free text search.
:returns: Search results.
"""
page = urllib.parse.urljoin(self.base_url, 'formatQuery.jsp')
params = dict(SEARCH_ALL=query,
d='libris',
f='simp',
spell='true')
response = self.session.get(page, params)
response.raise_for_status()
for row in parse_hitlist(response.text):
yield row
While writing the API it can be good to have a simple client to try it out with:
# libris_client.py
import libris
def main():
libris = libris.LibrisAPI()
for result in libris.search('Revised Report Scheme'):
print(result)
There is a shortcoming in this approach. The client is printing dicts. This ties the client to the specific format of the data returned by the parser, and makes it difficult for the client author to see how to get more information on an interesting search result.
Model the remote objects
The search method can yield custom objects instead. In general you
should have one class in your API for each type of object you think
the server stores in its backend. If it looks like they have a
database table for books and another table for authors, then you
should have a Book class and an Author class. It will make it easier
for you to model the relationships between the objects, since the data
and the operations will match the implementation on the server. You
will probably find that your objects have unique ids that the site
uses in its responses and requests. If the genres also have unique
ids then that’s a good indication that you need an Genre class.
Here’s one way that you can modify the API to return objects:
# libris.py
# ...
def search(self, query):
# ...
for row in parse_hitlist(response.text):
yield Book(self, row['id'], row['Referens'])
class Book(object):
def __init__(self, api, book_id, reference):
self._api = api
self._book_id = book_id
self.reference = reference
def __repr__(self):
return "<Book{!r>}".format((self._book_id, self.reference))
There are some questions of responsibility here. Should the Book object keep the whole row dict? Should the search method or a class method on the Book class handle parsing of the row dict? Should the Book class have a reference to the API or should all future requests go through the API class? It’s mostly a matter of taste and your own best judgment.
There are some benefits to the structure shown. If the Book object
receives all attributes that are currently known, as well as the API
object, then it can transparently send requests when more information
is needed (e.g. using Python’s @property decorator). The user of the
Book object doesn’t need to know that the page count is not shown in
the search hit list. There may also be more than one table that shows
books and they can have different sets of information displayed.
The user of the API shouldn’t need to know much about which requests are used to fetch what information. The Book object is also a natural point to add more methods that operate on books; it already has the book id and the API object.
While there are benefits to this setup, there are some dangers. As a user of the API you might not realize that you are using the site inefficiently. Suppose that you wanted to count how many pages there are in all of Charles Stross’s books added together. If the search hits don’t include page counts then your program will issue a request for each book. In a large automated system this can add up to significant overhead. Enable logging in your program and check if your request pattern makes sense.
A final note on the search method. Most sites implement a form of
pagination for search results. Each time you send a request you will
only get one page of results. This can be handled by going back to the
browser and looking for what response is sent when you go to the next
page. Document this and modify your search method. You will want to
create a loop that contains the current body of the method, and
updates the query parameters for each iteration of the loop so that it
gets the next page. A bonus of using yield in this situation is that
you will only send as many requests as you need.
All interactions with the site can be automated in this way.
Motivation for the business
A product owner for an old intranet site gets a call from your product owner. In turns out that there is no budget for new development of the site. They say that they can make an API if they get a budget. This will likely take at least half a year, if not more, and after that you will have an API that doesn’t do everything that the site does today. No budget is forthcoming. The site’s product owner stops being cooperative.
Alternatively your own product owner is sceptical about scraping the site. There are some big risks. The site might change drastically, all your efforts will be for nothing, and the business is now reliant on something that just doesn’t work anymore.
For the site’s product owner, there is probably not much you can do immediately. However, if you do decide to start scraping their site anyway, you will be doing them a big favor in the long run. Assuming that your product helps the business then they will have a good argument for why there should be a budget to develop a real API. (Just hope it’s a REST API and not SOAP).
Now for your product owner. He’s concerned that the site you’re scraping could drastically change and break your scraping code. Remind him that the they don’t have a development budget, so there is no way for them to implement any big changes. Since it’s an old intranet site the more realistic scenario is that it will be replaced by a completely different service (which hopefully does have an API).
Summary
Everything you can do in the browser, you can also automate. The major steps are: observing and documenting the site; test-driving parsers for responses; writing methods for requests; and creating classes for objects on the site.
Use the right tools for the job. For Python, the libraries Beautiful Soup and requests are a good combination.
Web scraping does not need to be difficult or messy and can help both your business, your project and the project of the site you’re scraping.
Addendum 2021-09-18: You’ll be much better off if you get the permission of the site’s owner before really deploying this type of solution. Also be sure to get an explicit OK in writing and keep up to date on changes in ownership. Ask about the operational risks with the increased the load on their site that your API brings. It might currently be scaled for manual usage only. Beware of politics.